The State of B2B Homepage Messaging 2026
Your homepage is now your most valuable pitch to your buyers and the machines advising them.
We scored 200 B2B homepages across 5 industries on 18 messaging criteria. The companies with the clearest story score 30% higher. And they’re the ones AI agents recommend.
AI agents are becoming the new front door for B2B buyers. When a buyer asks an AI "what’s the best tool for my problem," the agent reads your homepage and decides whether to recommend you. AI agents crawl your homepage and decide whether to recommend you. They read your words. That’s it. The clarity that earns a human’s trust in 7 seconds is the exact same clarity that earns a machine’s recommendation. This report shows who’s doing it, who’s not, and what separates them.
Author
Greg Rosner, PitchKitchen
Published
Sample
250 companies, 5 industries
01 - Executive Summary
The thesis
This report isn’t a scoring exercise. It’s evidence that the truth scales.
The companies that score highest on our rubric share one thing: they tell the truth about what they do, who they help, and what problem they solve. They don’t hide behind jargon or sprinkle ‘AI-powered’ on weak narratives. They name the villain. They name the transformation. And every word on their homepage sounds like it came from a real buyer’s mouth, not a product team’s whiteboard.
This matters now more than it ever has because of one structural shift: AI agents are becoming the new front door for buyers.
When a buyer asks ChatGPT, Claude, or Perplexity "what’s the best tool for my problem," the agent crawls your homepage and reads your words. That single paragraph decides whether you get recommended. Jargon fails both the human and the machine.
The companies with the clearest messaging are the ones machines recommend. The companies with AI-Parmesan ("AI-powered platform for enterprise solutions") are invisible to those same machines, because that sentence could describe 500 companies. There’s nothing to cite. Nothing to recommend. Nothing specific enough to match a buyer’s question.
This is the convergence: the same thing that makes a homepage work for a human visitor in 7 seconds (clarity, specificity, named problem, named transformation) is EXACTLY what makes it work for an AI agent crawling your site. The truth scales. Jargon doesn’t.
The 18 criteria in our rubric aren’t arbitrary. They measure how clearly a company tells the truth about itself. The tier gap that follows... T3 scale-ups outscoring T1 enterprise by 27%... exists because smaller companies HAVE to tell the truth. They can’t afford not to. Bigger companies can afford to be vague. Until now. Because the machines that decide who gets recommended don’t care about your brand equity.
In the age of AI agents, the truth is the one asset that compounds. Build it once. Deploy it everywhere. The companies at the top of this leaderboard aren’t doing anything magical. They’re just telling the truth about what they do. And in 2026, that truth is now readable by both humans and machines.
What we mean by the truth
The companies at the top of this leaderboard share one thing: they’ve clarified their story. They know who they’re for, what problem they solve, and what’s at stake if you do nothing. Whether they wrote it on a whiteboard or hired someone to build it, the clarity is there. And it shows in every sentence on their homepage.
What they may not have done yet is codify that clarity into a documented framework that AI can learn from. That’s the next step. Once you nail your story, you need to capture it in a blueprint... a brand guide, a messaging framework, something your team and your AI tools can reference every time they create anything. We call that the Magnetic Messaging Framework. Build it once. Deploy it everywhere.
This is just truth.
The companies you’d expect to win are losing.
We designed a scoring framework with 18 messaging criteria and trained Claude to apply it consistently across 250 homepages. The rubric was the judge. Claude was the instrument. Every page got the same test. Three patterns came back so cleanly they made us re-check the data. Every one of them inverts what the average CMO is currently buying.
Headline finding - The Tier Gap
27%
T3 scale-ups ($5-$50M) outscore T1 enterprise ($500M+) by 27% on messaging clarity. Every sector. No exceptions. The top 5 pages in the entire data set are all T3.
Why?Smaller companies HAVE to tell the truth. They can’t afford not to. Bigger companies can afford to be vague. Until now... the machines that decide who gets recommended don’t care about your brand equity. The T1 average isn’t a capability gap. It’s a choice gap.
Source: 250-company audit, May 2026. See section 06 for the full Tier Gap breakdown.
Three findings that should keep B2B CEOs up at night
01
T3 scale-ups outscore T1 enterprise by 27%.
$5-$50M scale-ups average 20 / 36 (n=76). $500M+ enterprise pages average 16 / 36 (n=61). Every sector shows the same pattern. Bigger isn’t better. Bigger is broken.
02
AI-Parmesan: the more you sprinkle, the worse you score.
Pages with zero AI mentions in the hero average 24 / 36. Pages with three or more AI mentions average 12 / 36. We coined ‘AI-Parmesan’ for the pattern... companies sprinkling ‘AI-powered’ on every line like parmesan on bad pasta.
03
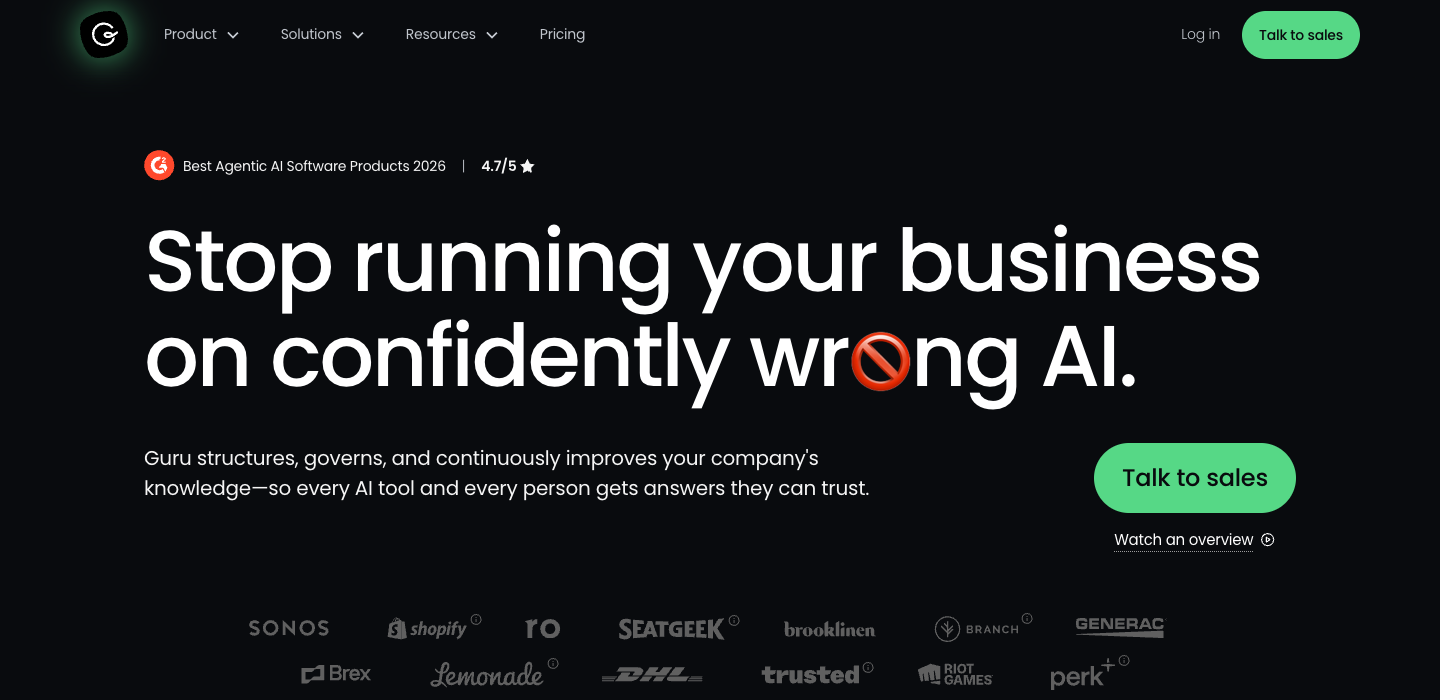
Every 28+ scorer names a specific villain.
Guru (33): ‘Stop running your business on confidently wrong AI.’ Housecall Pro (30): ‘The busywork runs itself.’ Contentful (30): ‘Sorry, content chaos... your time’s up.’ No villain, no top-tier score.
250
homepages scored
27%
T3 vs T1 score gap
2
hit Cost of Inaction
5/5
top scorers are T3
02 - The Verbal Layer
The part of your brand that machines can actually read.
Your brand identity has two halves: visual and verbal. Your visual identity is your logo, your colors, your photography, your design system. It's what makes your booth look good at a conference. It's what makes your homepage feel premium.
Your verbal identity is what you say. Your hero line. Your problem statement. Your rebellion. Your proof. It's what makes someone stay on the page past 7 seconds.
Here's the uncomfortable truth: LLMs can't see your visual identity. Not the logo. Not the colors. Not the $200K brand refresh. When an AI agent crawls your homepage to decide whether to recommend you, it reads your words. That's it.
The verbal half of your brand is the ONLY half that exists in the AI layer.
Most B2B companies invest 80% of their brand budget in visual and 20% in verbal. That ratio just became a liability. Because the machines that increasingly influence buying decisions are 100% verbal. They read your homepage the way a blind person reads a menu. If your words don't tell the truth about who you're for and what problem you solve, no amount of design will save you.
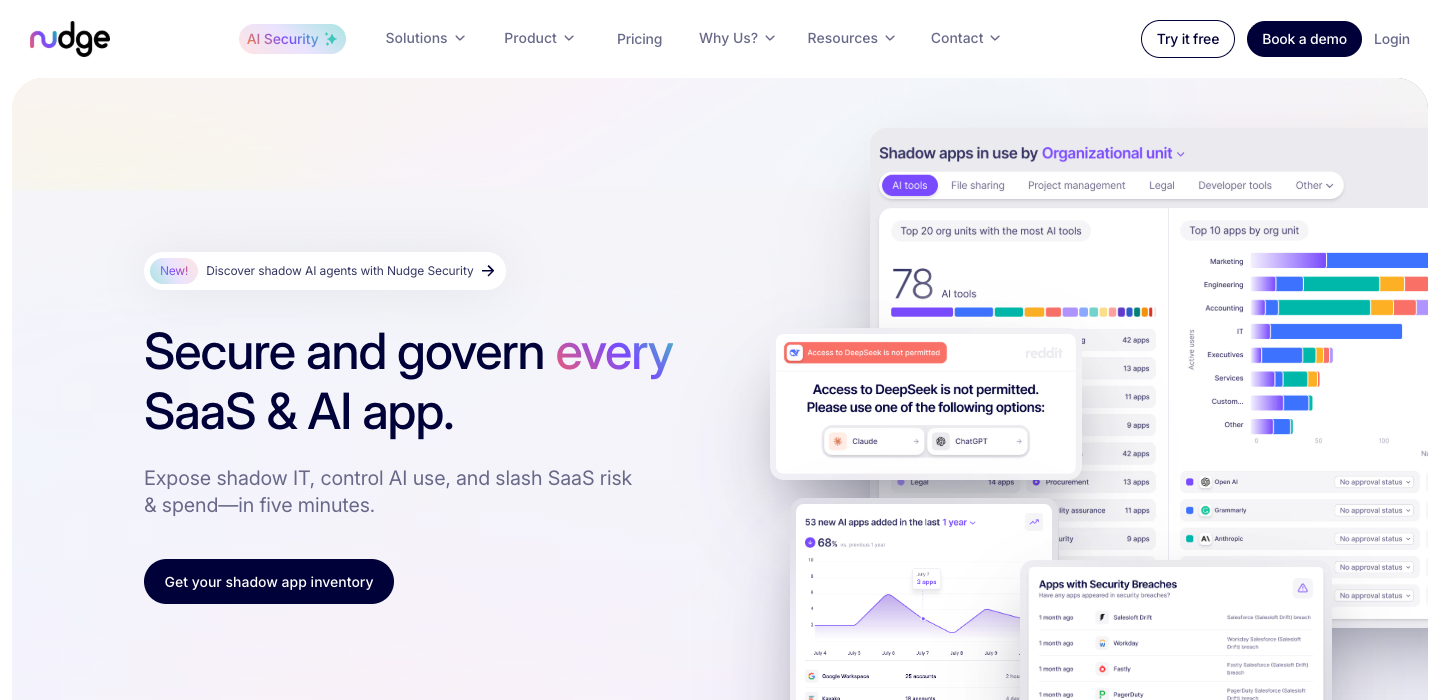
The companies at the top of this report didn't just have clear messaging. They had a verbal identity that works without the visual. Strip the logo off Nudge Security's homepage and the words still sell: "Modern work broke IT security." Strip the logo off Palantir's and you get: "AI-Powered Automation for Every Decision." One tells you something. The other tells you nothing.
Six pages that got it exactly right.
These aren’t just the highest scores. They’re the clearest examples of what it looks like when a company tells the truth in a way that works for both humans and machines.
94%
MAGNETIC
Cybersecurity · T3
Cybersecurity · T3
What they said
"Modern work broke IT security."
Named the problem in four words. Then backed it with 10-minute deployment vs 18-month legacy rollouts. Mandiant CEO endorsement.
83%
MAGNETIC
Wildcard · T3
Wildcard · T3
What they said
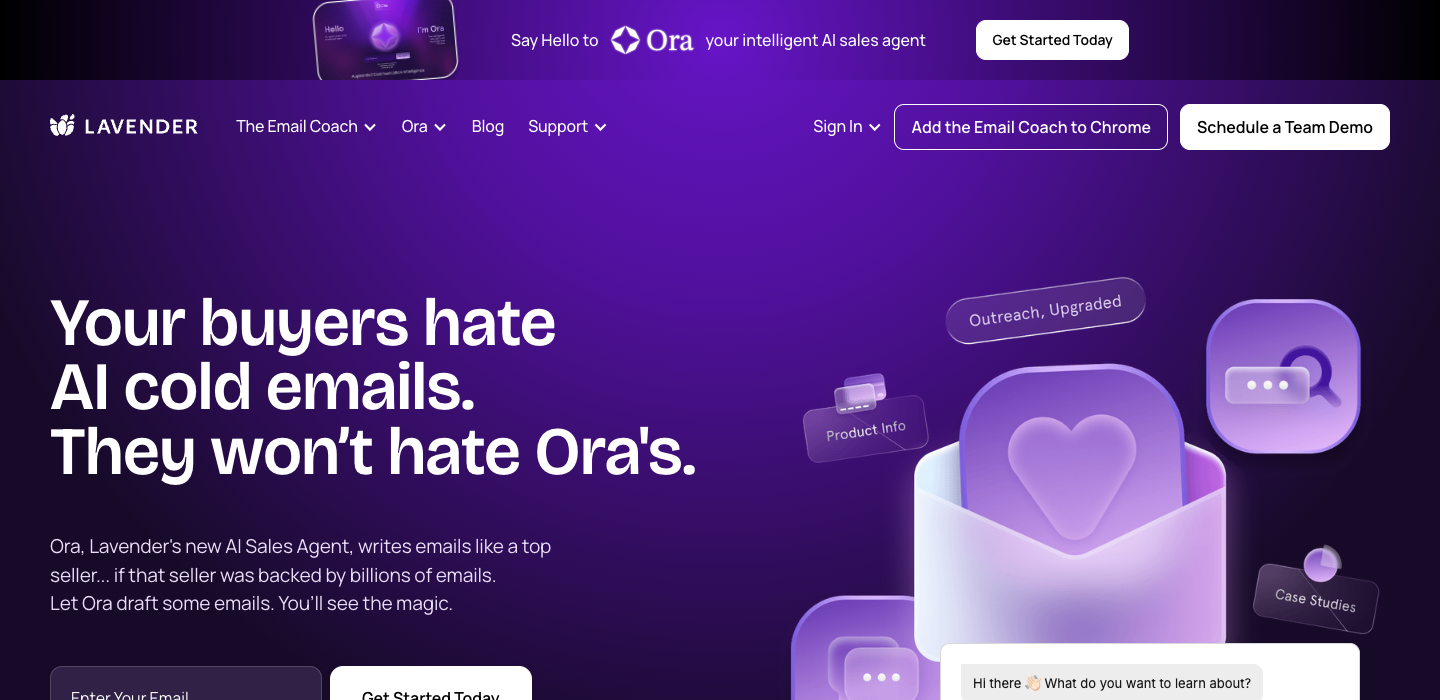
"The busywork runs itself."
Five words. Named the villain every plumber and electrician knows. Then proved it with “trained on 100M+ home service jobs.”
86%
MAGNETIC
Healthtech · T3
Healthtech · T3
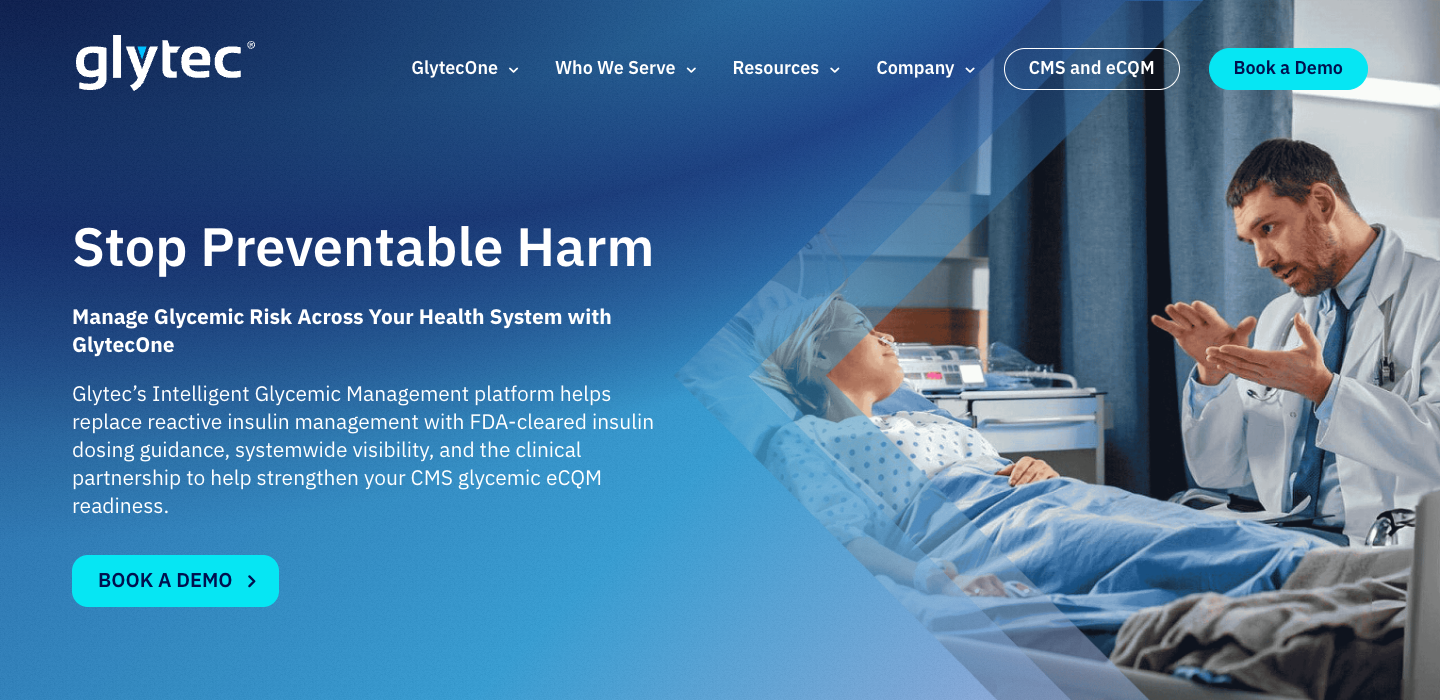
What they said
"Stop Preventable Harm"
A healthtech company with 1/100th the marketing budget of the enterprises it outscores. Clear problem-first messaging that tells clinicians exactly what Glytec does and why it matters. No AI-parmesan. No jargon. Just the truth about intelligent glycemic management.
Four pages that show what not to do.
These aren’t obscure companies. They’re names you know. And their homepages are a masterclass in what happens when messaging clarity gets sacrificed for brand posture, AI hype, or category-grabbing claims.


Why the worst scores matter for everyone.
CrowdStrike can afford a vague homepage. They’re CrowdStrike. Every CISO already knows what they do. The homepage just needs to validate what the buyer already believes.
But here’s the trap. Every conference you go to, there are 200 booths full of $10M-$50M companies whose homepages look like CrowdStrike’s. "AI-powered platform for [category]." They copied the enterprise playbook because it looks professional. But the enterprise playbook only works when you’re already the enterprise.
When you’re a $20M company, nobody’s looking for you by name. They’re asking an AI agent "what’s the best tool for [my problem]" and the agent is reading your homepage right now. If it says "AI-powered platform for enterprise security," the agent has nothing specific enough to recommend you. If it says "Modern work broke IT security," the agent can cite that sentence and point the buyer your way.
The enterprise playbook is a trap for everyone who isn’t an enterprise yet.
03 - Methodology
18 criteria. 4 categories. One rubric.
We designed a scoring framework with 18 messaging criteria and trained Claude to apply it consistently across 250 homepages. The rubric was the judge. Claude was the instrument. Every page got the same test.
Sample size
250
B2B homepages, scored by Claude.
Industries
6
Fintech, Healthtech, B2B SaaS, AI / Data, Cybersecurity, Wildcard.
Size tiers
3
$500M+ / $50M-$500M / $5M-$50M revenue.
1.Messaging Foundation
10 criteria
The 7-Second Test
In 7 seconds above the fold, can a stranger answer who this is for, what problem it solves, and what point of view it takes?
Scoring scale
- Stranger fails all three questions.
- Stranger gets one or two of the three.
- Stranger nails all three in under 7 seconds.
Rebellion / Movement
Is there a named enemy, named status quo, or named industry pattern the company is pushing against?
Scoring scale
- No enemy named. Generic positioning.
- Implied tension, but no concrete villain.
- A specific, named status quo is called out.
Unique Category Framing
Does the page coin or claim a category, sub-category, or named approach the buyer can recognize and repeat?
Scoring scale
- Reuses commodity category language only.
- Hints at a frame but doesn't name it.
- Owns a clearly named category or POV.
ICP Clarity
Can a visitor instantly see whether they're the intended buyer? Role, company size, stage, vertical.
Scoring scale
- No identifiable buyer signal at all.
- Vague (e.g. 'modern teams', 'growing companies').
- Buyer, stage, and context are unmistakable.
Problem Leadership
Does the page lead with the buyer's problem in their language, before the solution?
Scoring scale
- Solution-first or feature-first.
- Problem mentioned but generic.
- Problem is named in the buyer's own voice.
Customer-Centric vs. Narcissistic
Whose story is the homepage telling... the customer's transformation, or the company's history and capabilities?
Scoring scale
- Almost entirely about the company.
- Mixed, but tilts toward the company.
- The customer is the protagonist throughout.
Solution Clarity
Can a visitor explain what the company actually does in one sentence after reading the hero?
Scoring scale
- Buzzwords. No concrete solution.
- Roughly clear, but requires a second read.
- Crystal clear in one pass.
Cost of Inaction
Does the page name the price the buyer pays for not changing? Lost deals, slow growth, internal pain.
Scoring scale
- No mention of consequences of inaction.
- Soft consequences, mostly aspirational.
- Concrete, named cost of staying stuck.
Plan / Process with Outcome
Is there a visible 3-step (or numbered) plan that ties process to a specific outcome?
Scoring scale
- No process. Buyer can't see the path.
- Process listed but disconnected from outcome.
- Numbered plan + outcome, clearly linked.
Promised Land
Does the page paint a clear, specific 'after' state the buyer will live in once they choose this company?
Scoring scale
- Absent or counter-productive.
- Present but generic, weak, or incomplete.
- Specific, concrete, and well executed.
2.Trust & Evidence
4 criteria
Proof & Evidence
Are there concrete numbers, before/after deltas, or named outcomes (not just adjectives)?
Scoring scale
- No quantified results.
- Vague proof points (e.g. 'increased revenue').
- Specific, attributable, time-stamped numbers.
Social Proof
Customer logos, testimonials with names + titles + companies, video stories, named case studies.
Scoring scale
- No social proof or anonymous quotes only.
- Logos or quotes, but thin or unnamed.
- Named, role-attributed proof, ideally on video.
Authority & Credibility
Founder credentials, frameworks, original research, books, podcasts, awards. Why this team gets to talk about this.
Scoring scale
- No authority signals.
- Generic credentials (years, funding raised).
- Distinct authority assets (IP, frameworks, body of work).
Alternatives Acknowledged
Does the page address the buyer's other options honestly... including 'do nothing' or competitors by name?
Scoring scale
- Pretends to be the only option.
- Vague 'unlike other tools' language.
- Names the alternatives and the trade-offs.
3.AI Readiness
3 criteria
AI-Parmesan Index
How heavily does the page sprinkle 'AI-powered', 'AI-enabled', 'AI-first', 'agentic' without saying what the AI does?
Scoring scale
- Heavy AI-Parmesan with no substance.
- Some AI buzzwords, partially explained.
- AI claims are specific, mechanistic, and proven.
LLM Quotability
When an LLM crawls this page, are there clean, declarative, citation-ready sentences it can lift into an answer?
Scoring scale
- Marketing fluff. Nothing extractable.
- Some quotable claims, mostly buried.
- Multiple short, declarative, citation-ready lines.
Copyright Freshness
Visible 'last updated' date, recent dates on case studies, and a current copyright year. AI engines weight recency.
Scoring scale
- Stale or missing dates. Year is 2+ behind.
- Copyright current; content undated.
- Visible recent updates and current copyright.
4.Conversion
1 criterion
CTA Hierarchy
Is there one obvious primary CTA, plus a soft secondary path for visitors not ready to buy? No CTA jungle.
Scoring scale
- No CTA, hidden CTA, or 6+ competing CTAs.
- Primary CTA present but buried or unclear.
- One clear primary, one obvious soft secondary.
04 - The Science Behind the Score
18 criteria. Seven frameworks. Decades of proof.
None of these 18 criteria were invented for this report. Every one of them traces back to frameworks proven by the people who've shaped how B2B companies communicate. We built the rubric by stress-testing what the best in the field have already published, then asking one question: does this show up on the homepage or doesn't it?
The Strategic Narrative
Andy Raskin
- Problem Leadership
Raskin’s “Name a Big, Relevant Change”: lead with the shift, not your product
- Named Villain
His “winners and losers” framing requires naming what’s losing
- Transformation Arc
Raskin’s “Promised Land” is the before/after that pulls the buyer forward
- Cost of Inaction
The losers in Raskin’s framework are the ones who don’t move
- Social Proof
Raskin’s “Evidence You Can Make It Happen” is proof, not logos
Positioning
April Dunford
- Cover-the-Logo Test
If a competitor could say the same thing, your positioning has failed
- Three Questions Test
Her “what, for whom, why now” maps directly
- Named Villain
Dunford calls these “competitive alternatives”
- Specificity
Her framework demands concrete value claims, not vague promises
StoryBrand
Donald Miller
- 7-Second Test
StoryBrand’s “grunt test”: can a caveman look at your site and know what you offer?
- Problem Leadership
Starts with the character’s problem, not the guide’s solution
- CTA Clarity
Obsessive about clear, direct calls to action
- Transformation Arc
“Success and failure” endpoints are the before/after
- Cost of Inaction
StoryBrand calls this “the stakes”
Category Design
Category Pirates
- Rebellion / POV
A missionary company has a point of view. A mercenary doesn’t
- AI-Parmesan
They’d call this “better sameness”
- Named Villain
They name the old way of thinking, not just competitors
- LLM Quotability
Their “languaging” work is what makes a company citable by humans and machines
Permission and Tension
Seth Godin
- Buyer Language
“People like us do things like this”
- Rebellion / POV
“Tension” is the gap between how things are and how they should be
- Emotional Resonance
Marketing that doesn’t make you feel something doesn’t work
- Brand Signal Score
Nobody cares about your company. They care about themselves
Intention-Based Marketing
Frank Kern
- Transformation Arc
“Results in advance”: show the before/after before the buyer commits
- CTA Clarity
Ruthlessly clear about the next step
- Specificity
Famous for concrete numbers and specific outcomes
- Authority Signal
Authority is demonstrated, not claimed
The Magnetic Messaging Framework
Greg Rosner / PitchKitchen
- Brand Signal Score
The MMF’s “mirror test.” If your homepage talks about you more than your buyer’s problem, you’ve already lost
- Rebellion / POV
Requires a clear point of view that some people will disagree with
- Named Villain
Every MMF engagement identifies a specific enemy the buyer is already fighting
- Buyer Language
Pulls language directly from buyer conversations, not internal brainstorms
- Three Questions Test
The “stranger at a dinner party” test
- AI-Parmesan
A term coined by PitchKitchen for this report
- LLM Quotability
The MMF’s AI Brand Twin thesis: messaging now has to work for both human buyers and the AI agents advising them
The Overlap Is the Point
Some criteria show up under multiple frameworks. Named Villain appears in Raskin, Dunford, and Category Pirates. Problem Leadership shows up in Raskin, StoryBrand, and Godin. Rebellion / POV runs through Godin, Category Pirates, and Raskin.
That's not a weakness in the rubric. It's validation. When seven independent frameworks all say “name a villain,” and 190 out of 205 companies in our dataset don't, that's not a style preference. It's a structural gap in how B2B companies communicate.
The 18 criteria aren't 18 opinions. They're 18 consensus points from the people who've spent decades studying what makes B2B messaging work. We just measured whether anyone's actually doing it.
05 - Sector Deep Dives
Six sectors. Six different stories.
Six sectors. 250 homepages, scored against the same rubric. Each card shows the sector verdict, the top scorer, the bottom scorer, and what the data revealed.
Sector 01 of 6
Fintech
56%
INVISIBLE
20 fintech homepages... half infrastructure providers, half embedded finance, half consumer. The cleanest tier gap in the entire dataset.
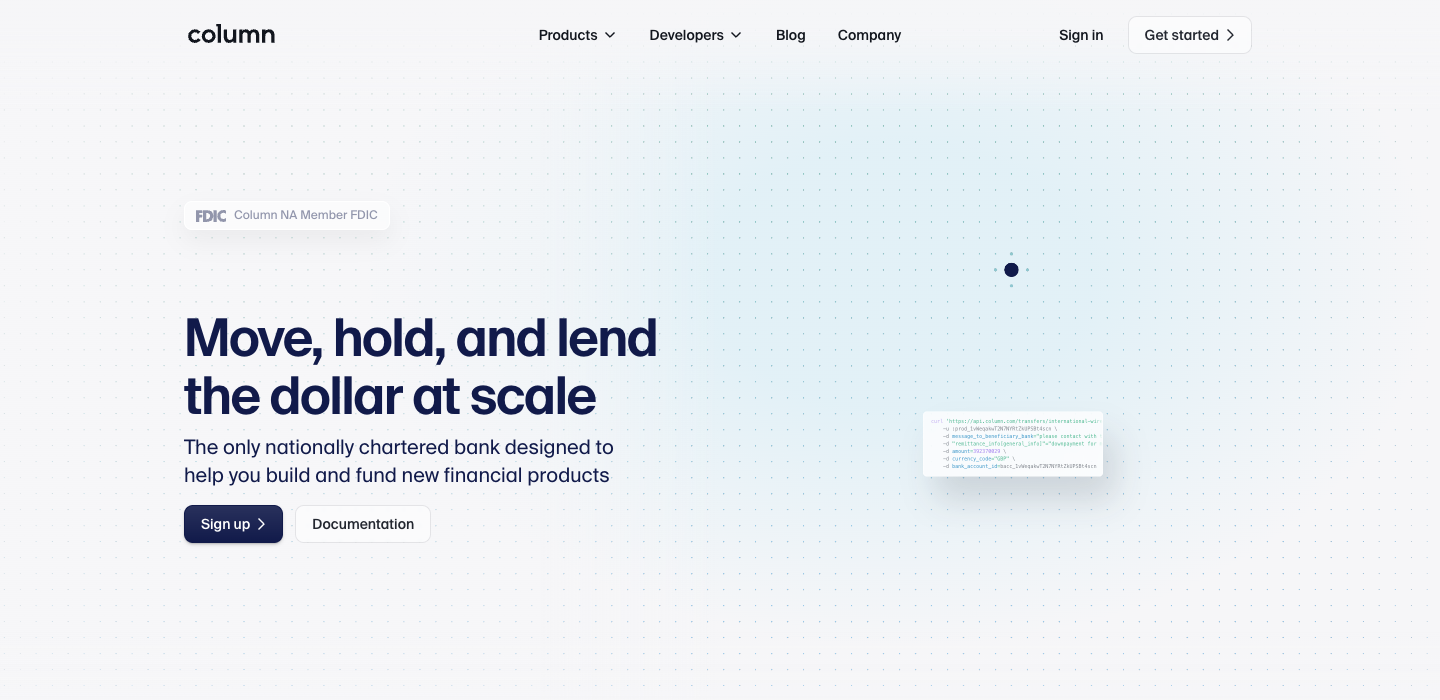
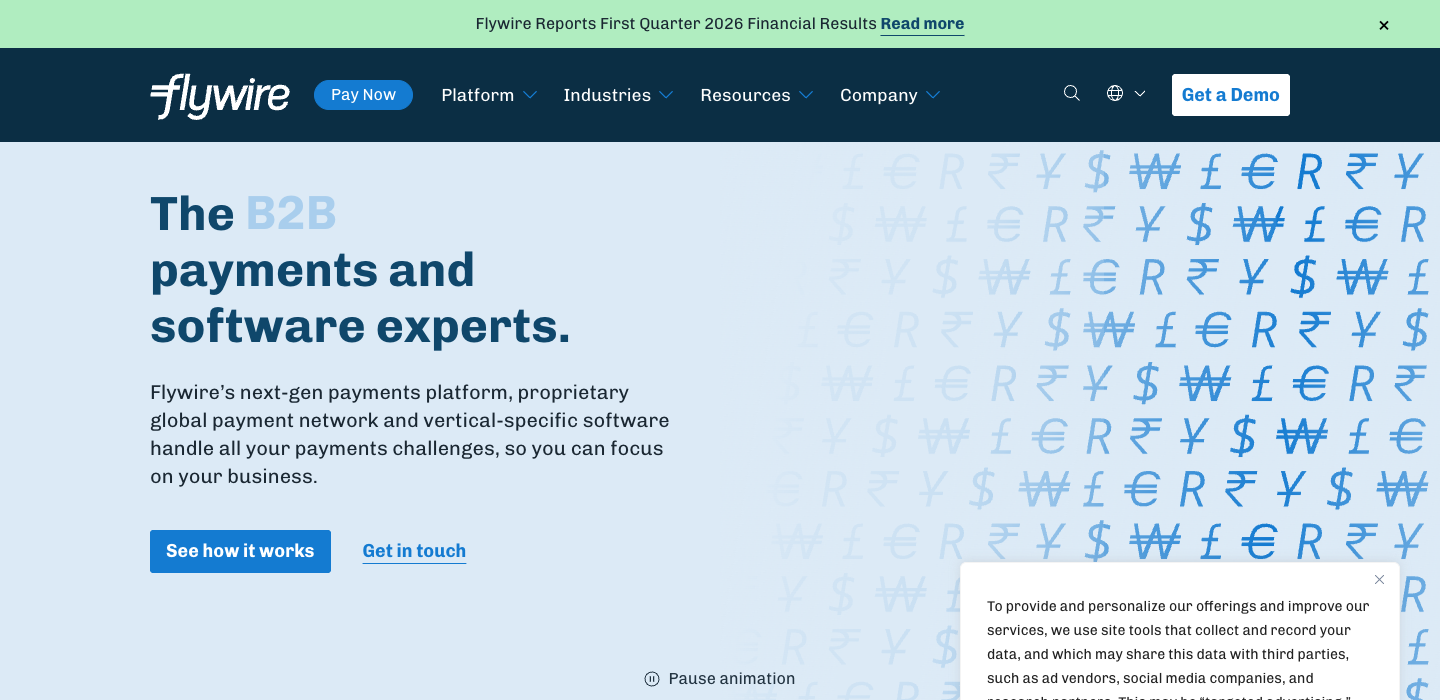
What this means
Column (Magnetic) and Increase (Magnetic), both T3, score higher than ANY T1 in any sector. Both have zero AI mentions, developer-native language, and named villains (middleware, abstraction). T1 fintechs like Flywire and nCino lead with generic platform claims.
Sector 02 of 6
Healthtech
51%
INVISIBLE
17 healthtech homepages... RCM platforms, clinical AI vendors, primary-care infrastructure. Second-highest scoring sector overall.
What this means
T1 companies like Epic and Athenahealth lead with mission statements, not buyer problems. T3 companies like Glytec, DeepScribe, and Artera lead with the clinician’s pain: documentation burden, broken patient communications, after-hours burnout. Elation Health’s ‘Working after hours is DESTROYING primary care’ is one of only two pages in 250 to name the cost of inaction.
Sector 03 of 6
B2B SaaS
51%
INVISIBLE
82 B2B SaaS pages... the most crowded sector in the dataset and the most generic. Where the named-villain pattern is clearest.
What this means
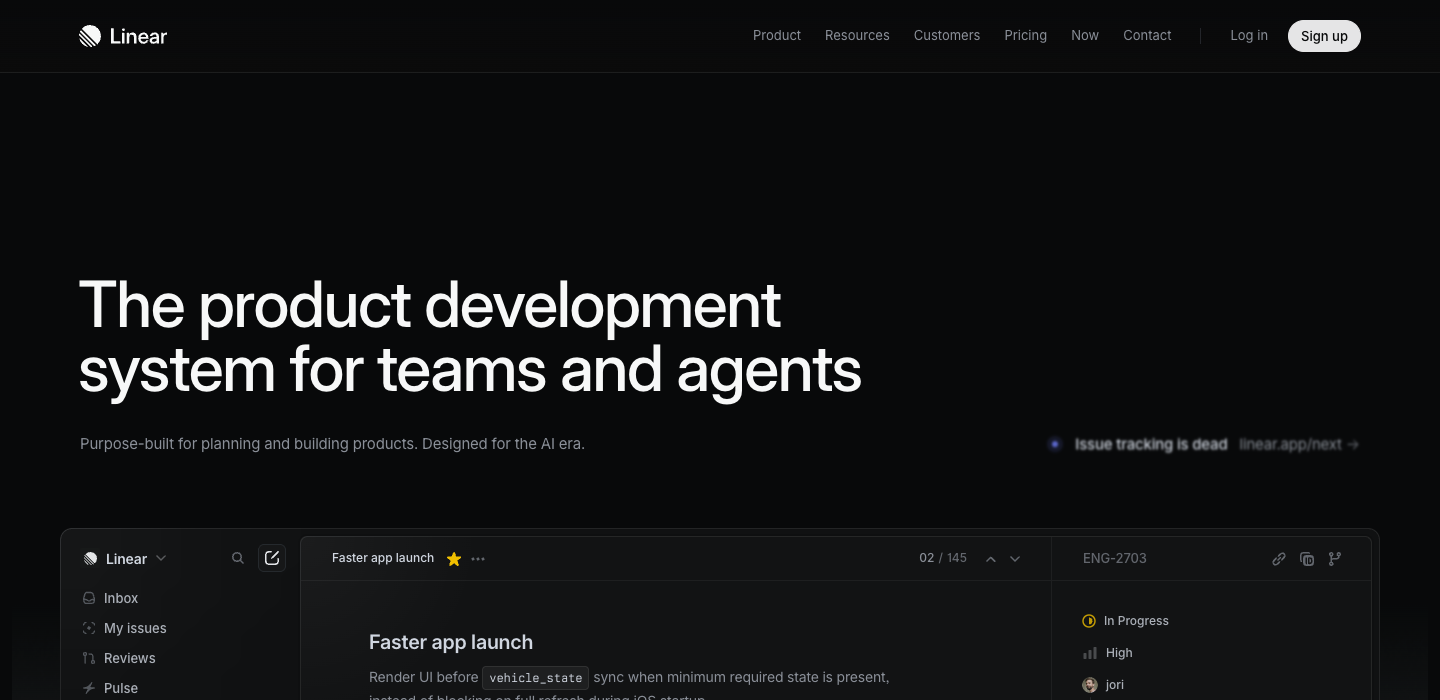
T1 heroes like ‘Outpace everyone’ (Monday) and ‘Unleash your teams’ (Atlassian) could belong to any company. T3 standouts like Close CRM, Guru, Lavender, and Fathom win by naming villains... wrong AI, hated emails, forgotten meetings. Linear is the T2 exception with ‘Issue tracking is dead.’
Sector 04 of 6
AI / Data
51%
INVISIBLE
32 AI and data infrastructure homepages, from LLM platforms to vector DBs and orchestration. The starkest tier gap in the dataset.
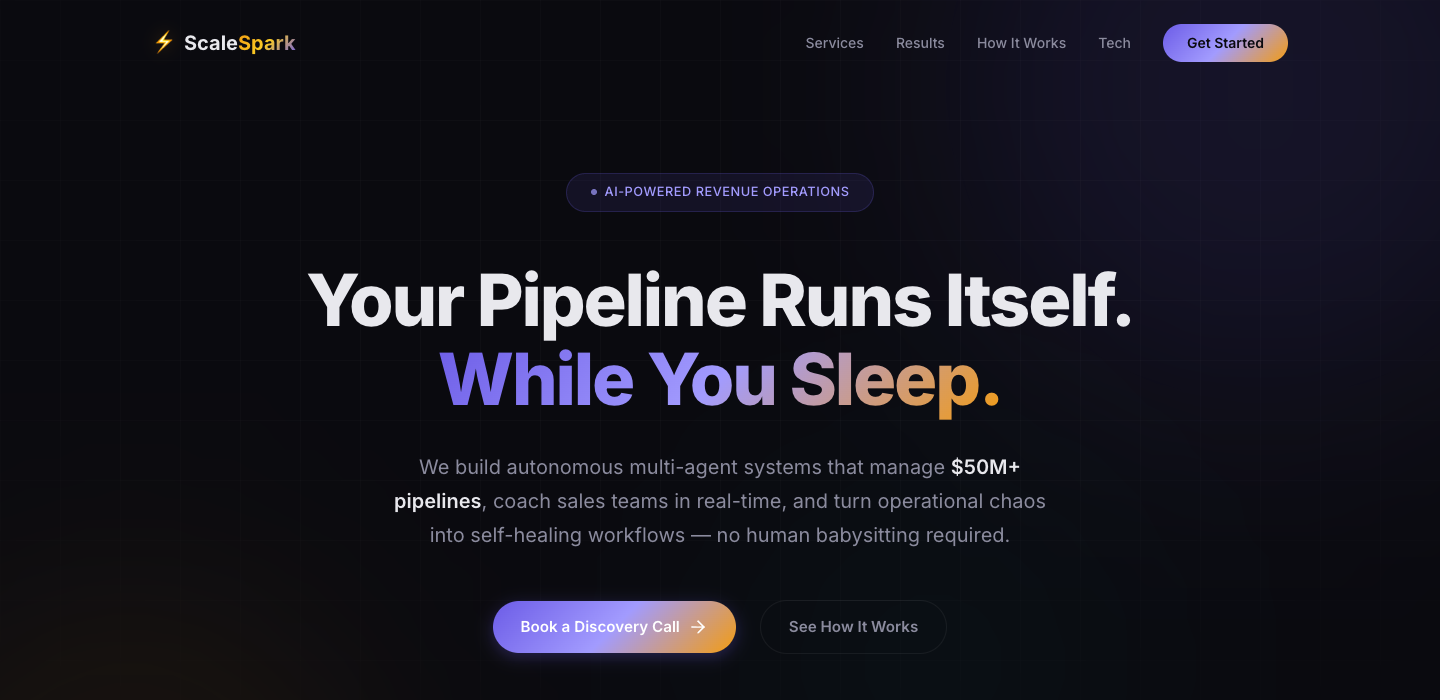
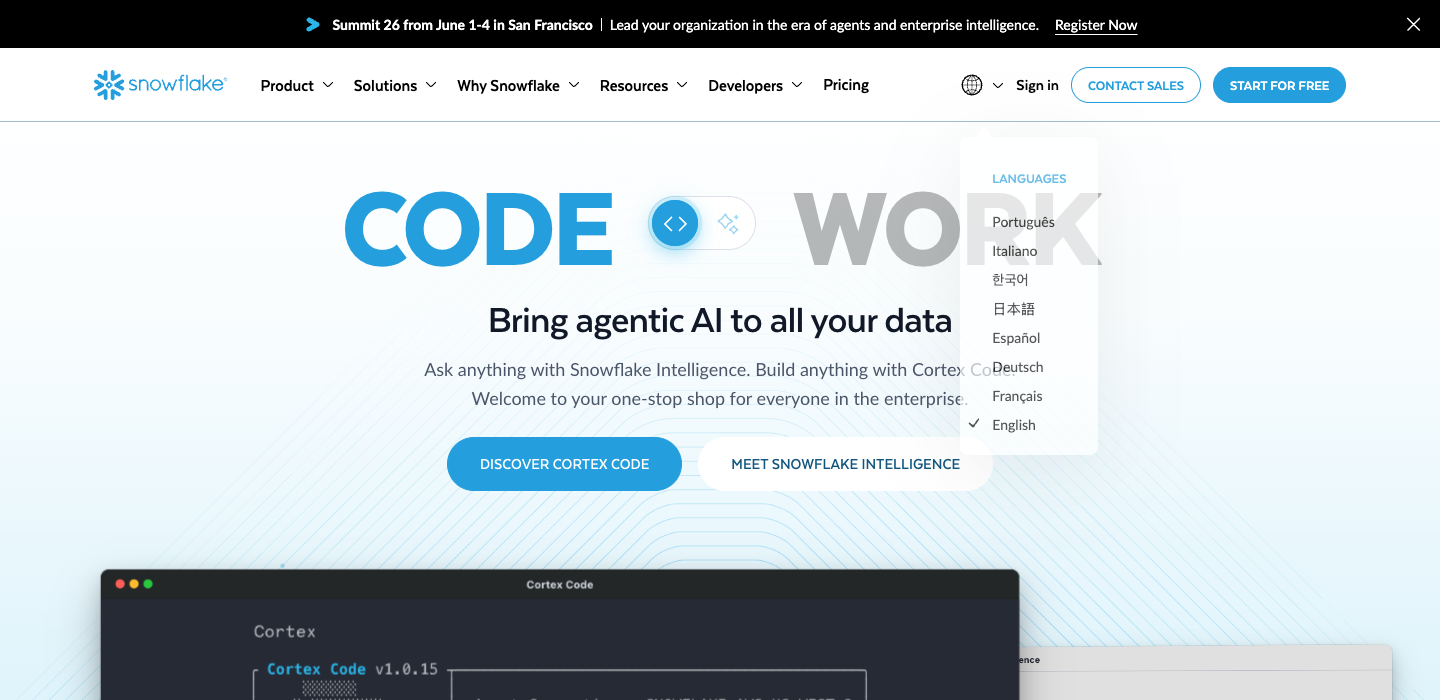
What this means
T1 averages Critical (Palantir, Snowflake, C3.ai). T3 averages Approaching (Neon, Dagster, Supabase). Developer-first T3 companies with code on the homepage dramatically outperform enterprises with product-catalog heroes. The category most likely to be quoted by AI engines is the worst at giving AI engines anything to quote.
What these heroes actually look like
Sector 05 of 6
Cybersecurity
48%
INVISIBLE
24 cybersecurity homepages from EDR, SOAR, identity, and platform vendors. T1 cybersecurity is the worst-scoring sub-segment in the entire dataset.
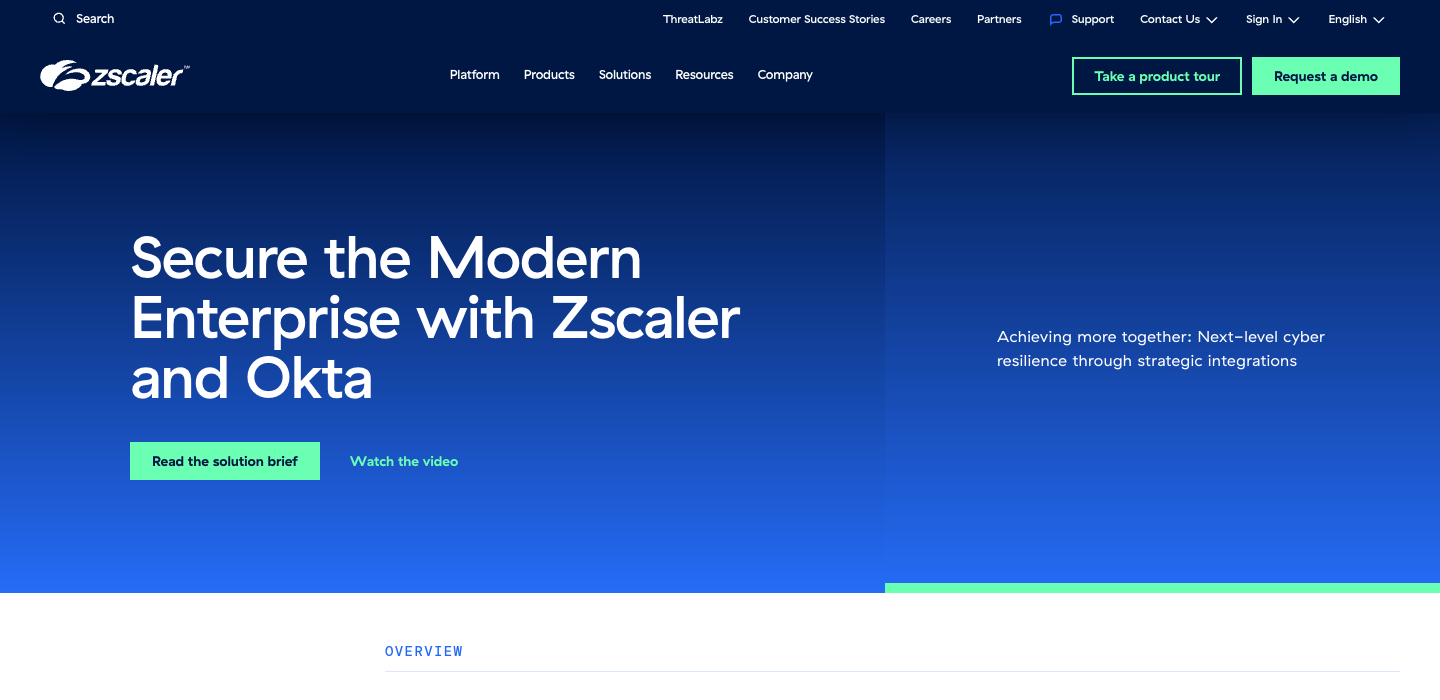
What this means
CrowdStrike, Zscaler, Fortinet, Varonis, Qualys all land Critical or Weak. These companies sell to CISOs, the most informed buyers in B2B, and their homepages say the least. T3 co-leader Nudge Security shows what’s possible: ‘Modern work broke IT security.’
What these heroes actually look like
Sector 06 of 6
Wildcard (cross-sector)
46%
INVISIBLE
44 cross-sector companies that don’t fit the 5 main industry buckets... HR Tech, Legal Tech, Construction Tech, Supply Chain, Sales Enablement. Vertical SaaS dominates.
What this means
ServiceTitan, Housecall Pro, Buildertrend... companies serving specific trades score higher because verticality forces messaging clarity. Clio stands out in legal with ‘Standard software tracks your work. Clio moves it forward.’ Named villain, named rebellion, one sentence.
What these heroes actually look like
06 - The Tier Gap
Bigger isn’t better. Bigger is broken.
Three tiers, head to head. T1 ($500M+ enterprise), T2 ($50M-$500M mid-market), T3 ($5M-$50M scale-up). The hypothesis going in: the bigger the company, the sharper the messaging. The data went the other way... by a lot. T3 outscores T1 by 27%. Every sector shows the same pattern. The top 5 pages in the entire 250-company set are all T3.
T1 Enterprise
$500M+
INVISIBLE
T2 Mid-Market
$50M-$500M
INVISIBLE
T3 Scale-Up
$5M-$50M
INVISIBLE
Average score by tier (out of 100%)
- T1 Enterprise ($500M+)44%
- T2 Mid-Market ($50M-$500M)49%
- T3 Scale-Up ($5M-$50M)56%
T3 scale-ups average 57%. T1 enterprise averages 44%. T3 outscores T1 by 27% relative. Every sector shows the same pattern.
Top 5 scorers, full data set
All T3. Not one enterprise.
"Modern work broke IT security."
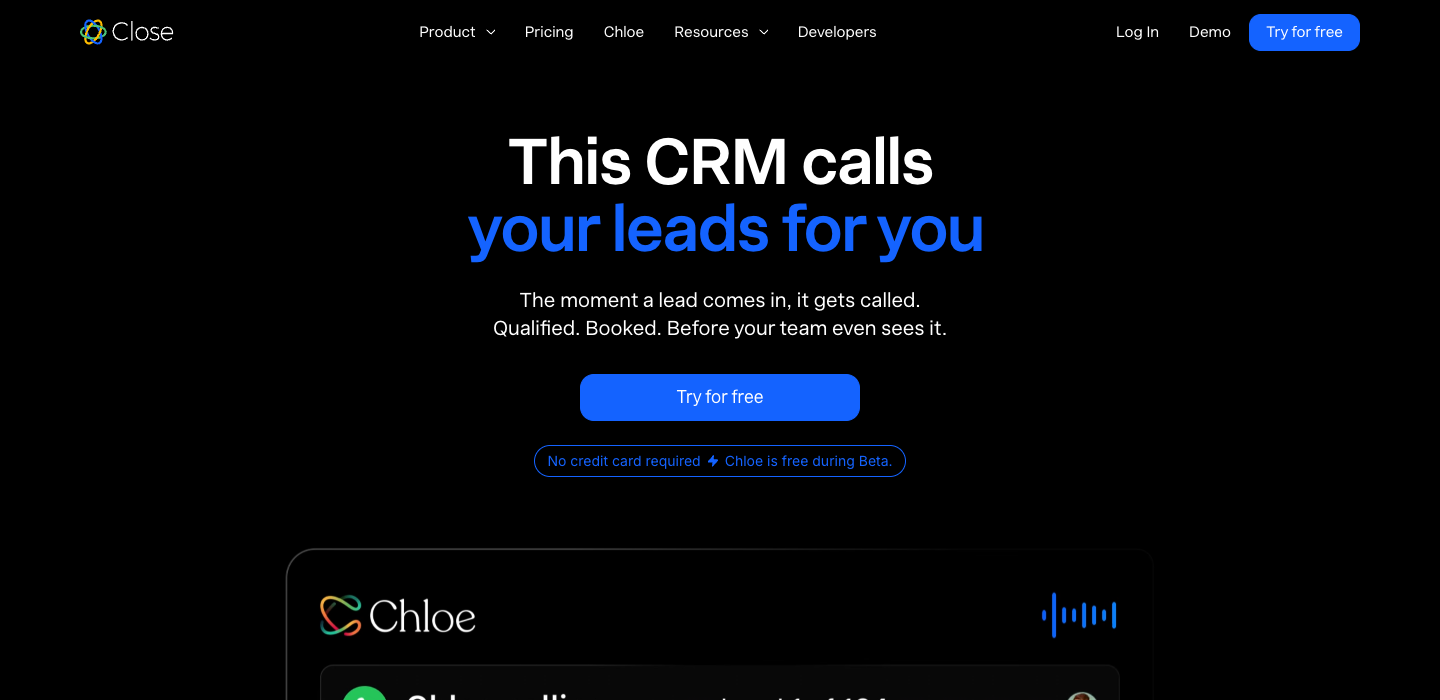
"This CRM calls your leads for you."
"Move, hold, and lend the dollar at scale."
"Stop running your business on confidently wrong AI."
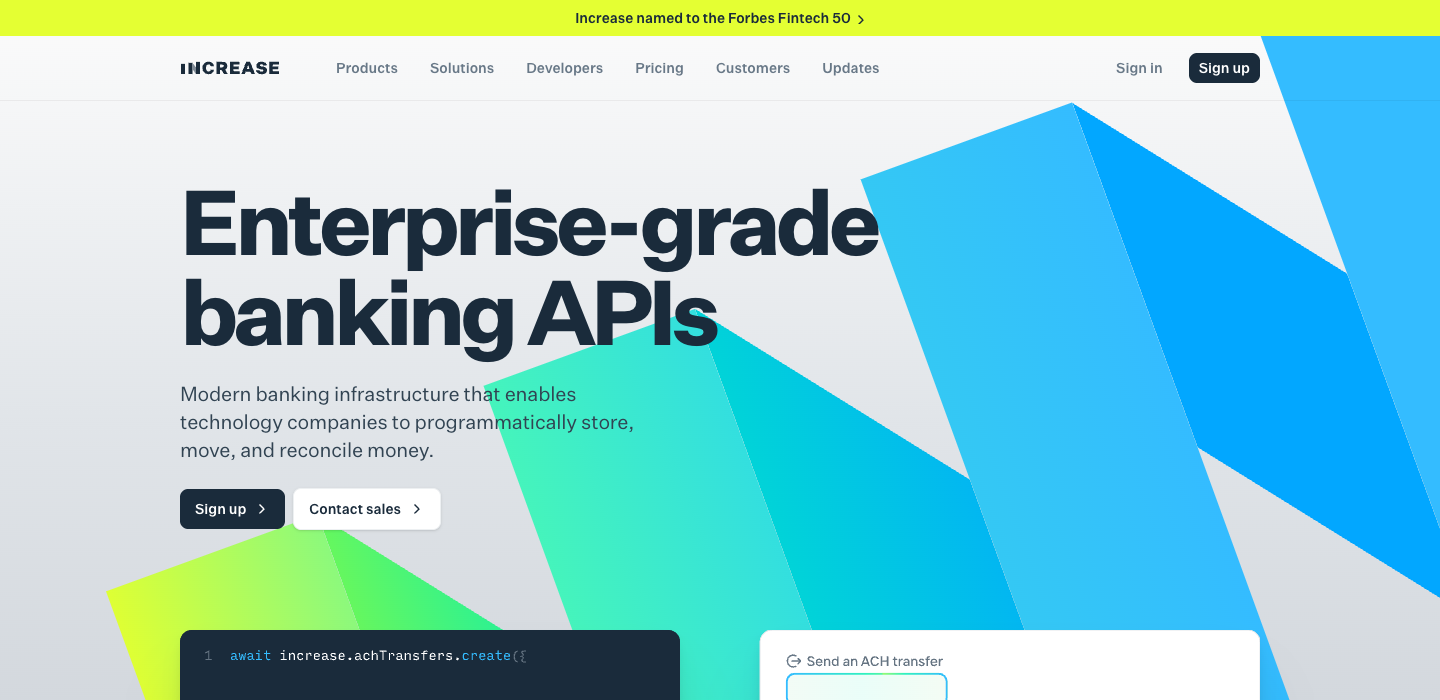
"Enterprise-grade banking APIs."
Both co-leaders sell AI products. Both have zero AI mentions in their hero. Counter-data point: Waystar (T3) scored 14% (CRITICAL). Size doesn’t guarantee clarity in either direction... but across all 250 pages, T3 leads the leaderboard top to bottom.
What the gap shows
The hypothesis going in: bigger budgets, dedicated brand teams, and longer history would translate into sharper messaging at the top of the market. The data simply does not support that hypothesis. Across all six sectors in the 250-company audit, T3 leads. T2 sits closer to the bottom than the top. T1 trails. Bigger isn’t better. Bigger is broken.
Why T1 companies score worse
It’s not that T1 companies have worse marketers. It’s that they have more reasons to be vague. Five structural forces make enterprise messaging generic by default.
01
Committee copy
T1 homepages go through legal, brand, product marketing, corporate comms, and the CMO’s office. Every stakeholder removes something specific and replaces it with something safe. “We help healthcare providers reduce documentation burden” becomes “AI-powered solutions for the modern enterprise.” The specificity gets sanded down by consensus.
02
Multi-product sprawl
Column sells one thing (banking APIs). Salesforce sells 47 things. When you sell everything, your homepage can’t say anything specific. So you retreat to ‘the #1 platform for [category]’ because no single product owns the hero. The homepage becomes a lobby, not a pitch.
03
Brand equity as a crutch
CrowdStrike doesn’t need to explain what they do. Everyone in cybersecurity already knows. So the homepage becomes a product launch poster or an event promo instead of a messaging page. They can afford to be vague because their brand does the work. Until an AI agent crawls the page and has no brand context. Then the vagueness kills them.
04
Fear of limiting the TAM
T3 companies like Close CRM say “This CRM calls your leads for you” because they know exactly who they’re for: sales teams that need faster lead follow-up. T1 companies won’t say that because it excludes the 90% of their TAM that doesn’t have that specific problem. So they say “AI-powered CRM for the enterprise” which includes everyone and resonates with no one.
05
The AI-Parmesan panic
In 2025-2026, every board is asking ‘what’s our AI story?’ T1 companies respond by sprinkling AI across the homepage whether it belongs there or not. ‘Agentic.’ ‘AI-native.’ ‘AI-powered.’ It’s defensive positioning, not buyer communication. They’re signaling to Wall Street, not speaking to customers.
What’s at risk for T1 companies
This isn’t just a branding problem. It’s a distribution problem. Three things are converging at the same time.
01
AI agents are becoming the new front door.
When Perplexity, ChatGPT, or Claude recommends a product, it cites the homepage. If your homepage says ‘AI-powered automation for every decision’ (Palantir, 22% - CRITICAL), the AI agent has nothing to cite. If your homepage says ‘Modern work broke IT security’ (Nudge Security, 94% - MAGNETIC), the agent can cite that sentence to recommend you. The companies with the clearest messaging will win the AI recommendation layer. The vague ones become invisible.
02
The production layer died, but nobody fixed the story.
AI made content production essentially free. Every company can now publish 30 posts a month. But the STORY underneath those 30 posts didn’t change. If the homepage is generic, the 30 posts are generic at scale. More content, same message, zero compounding. The companies that invested in a clear narrative (what we call the Magnetic Messaging Framework) before scaling content are the ones whose content compounds. Everyone else is producing the consensus view of their industry with their logo on it.
03
The buyer’s attention bar went through the roof.
When every company sounds the same, the only content that cuts through is content that says something the consensus doesn’t. T3 companies are forced to say something different because they can’t outspend their competitors on distribution. T1 companies CAN outspend, so they never face the constraint that forces clarity. Until the market shifts and outspending stops working.
The punchline
The T1 messaging gap isn’t a capability gap. It’s a choice gap.
Zapier (83% - MAGNETIC) and PagerDuty (72% - APPROACHING) prove that T1 companies CAN score well. They just have to choose clarity over safety. Most choose safety. And in 2026, safety is the most dangerous choice you can make. Because the machines that decide who gets recommended don’t grade on a curve for brand equity.
07 - The Named Villain Playbook
Every page scoring 28+ names a specific villain.
The pattern was the most consistent in the entire dataset. Every single homepage that scored 28 or higher named something specific the buyer is currently fighting... wrong AI, hated emails, forgotten meetings, content chaos, after-hours burnout, middleware abstraction, generic enablement. No villain, no top-tier score. The mirror, not the threat.
83%
MAGNETIC
Wildcard · T3
Wildcard · T3
Named villain: busywork in the trades
"The busywork runs itself."
AI mention buried in the sub. Hero is about the outcome (busywork), not the technology.
83%
MAGNETIC
B2B SaaS · T2
B2B SaaS · T2
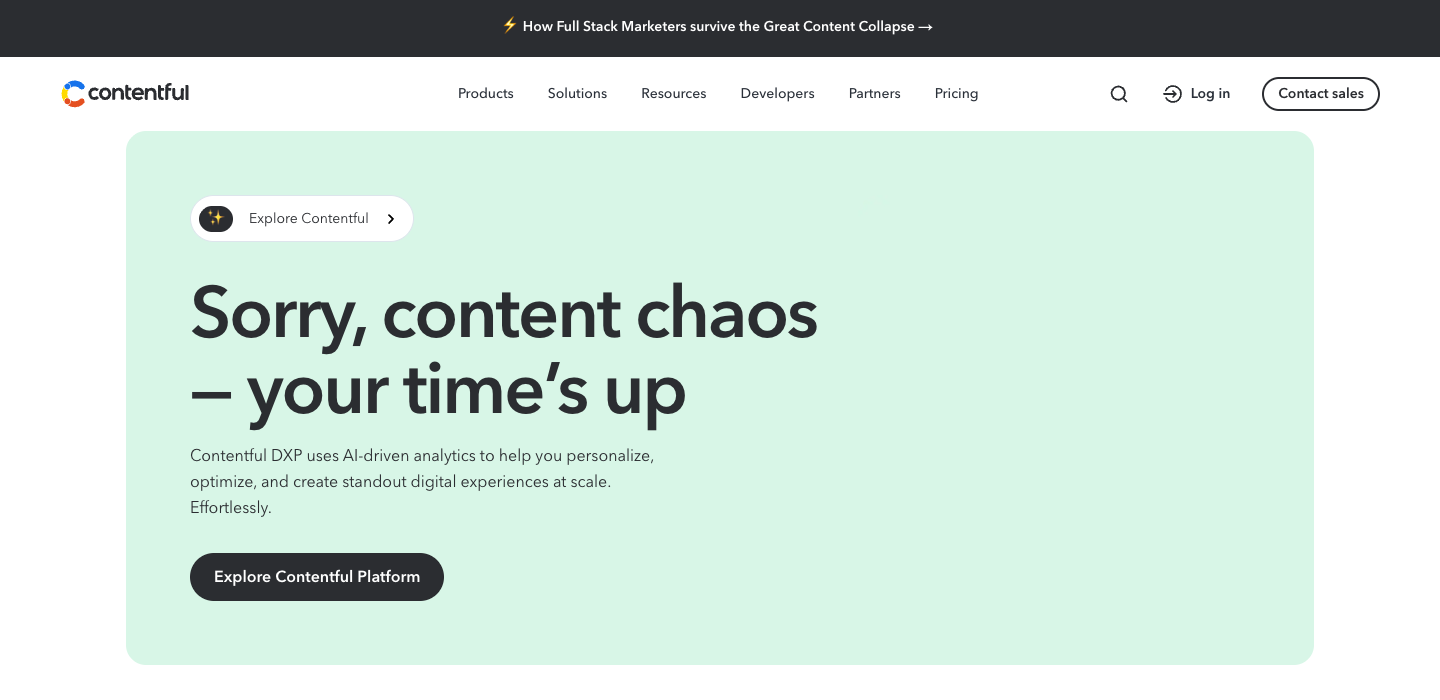
Named villain: content chaos
"Sorry, content chaos ... your time’s up."
Names something the buyer is feeling RIGHT NOW. ‘Sorry’ is the killer word. It’s the firing notice.
83%
MAGNETIC
B2B SaaS · T3
B2B SaaS · T3
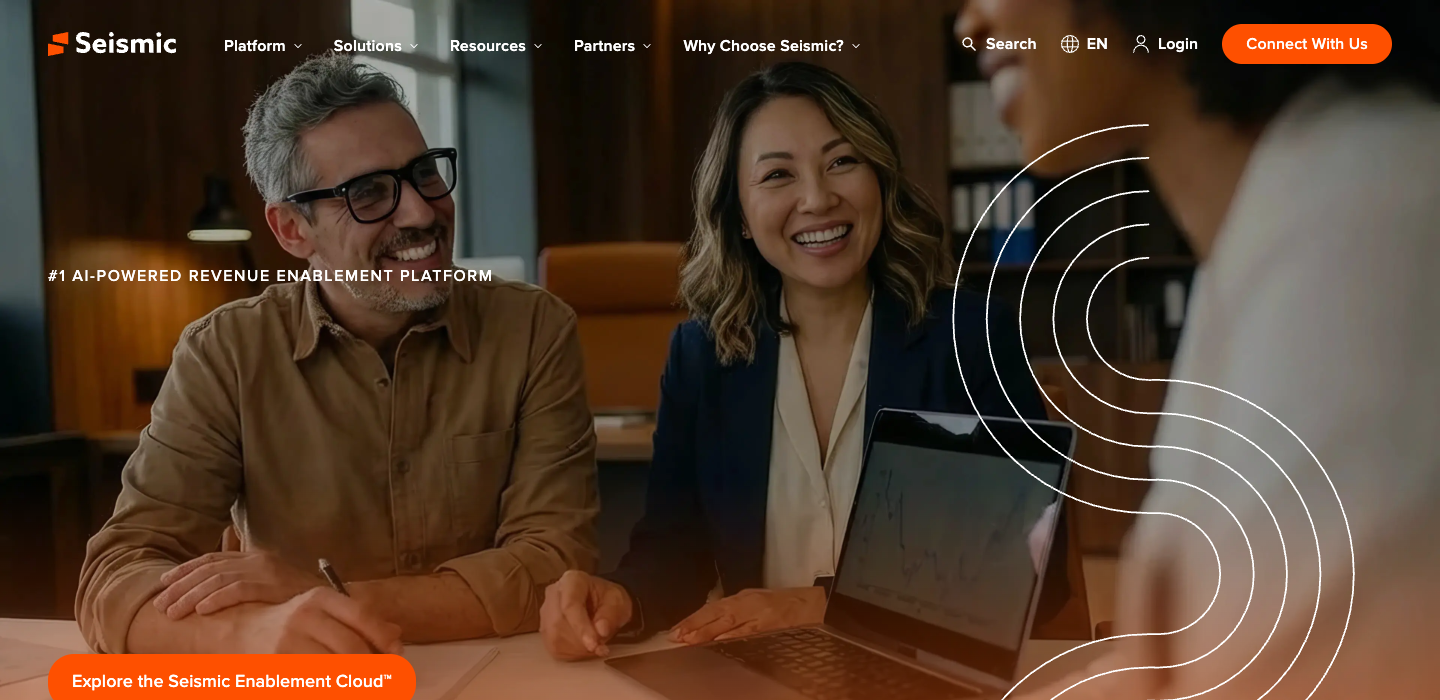
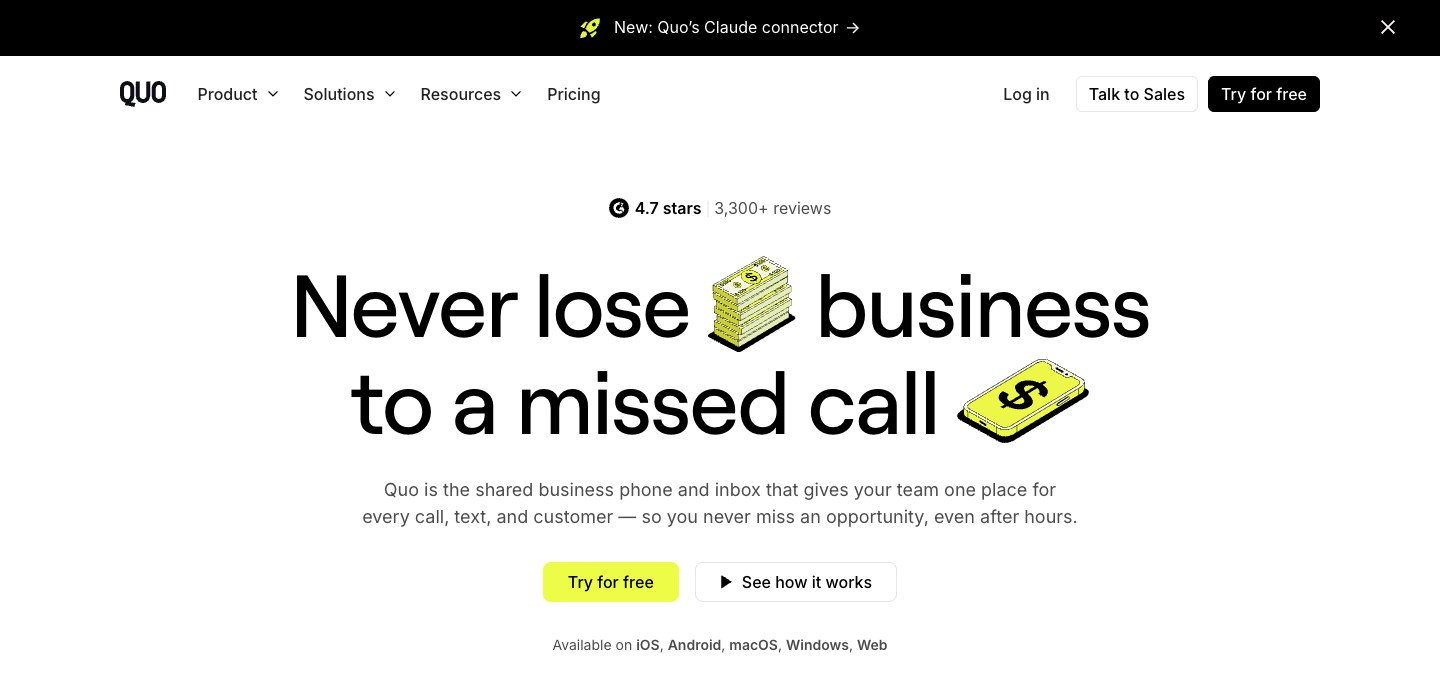
Named villain: missed calls = lost revenue
"Never lose business to a missed call."
Names the cost of inaction in 7 words. Most pages can’t do this in 70.
83%
MAGNETIC
B2B SaaS · T1 (highest T1 score)
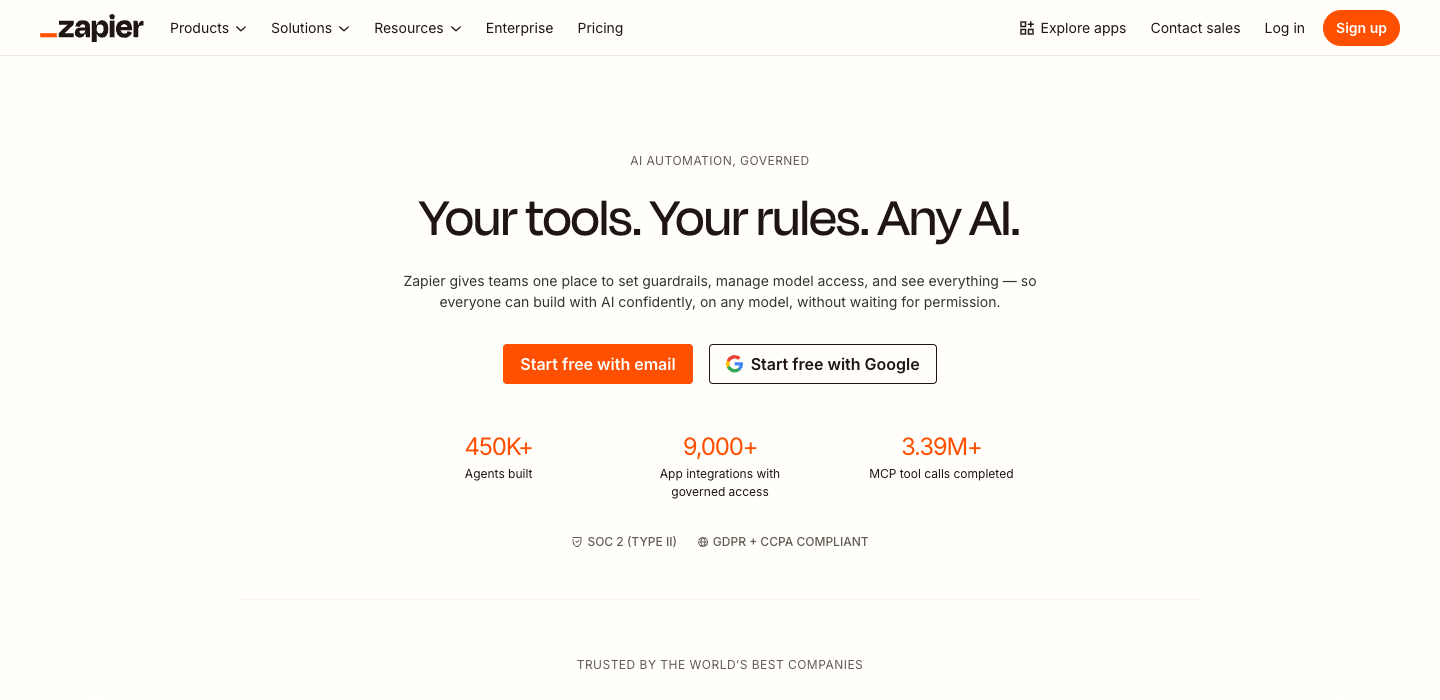
B2B SaaS · T1 (highest T1 score)
Named villain: waiting for permission
"Your tools. Your rules. Any AI."
Same resources as Salesforce or Snowflake. Chose buyer-first, rebellion-forward, specific. Proof: 450K agents. The T1 ceiling exists by choice, not capability.
78%
APPROACHING
Healthtech · T2
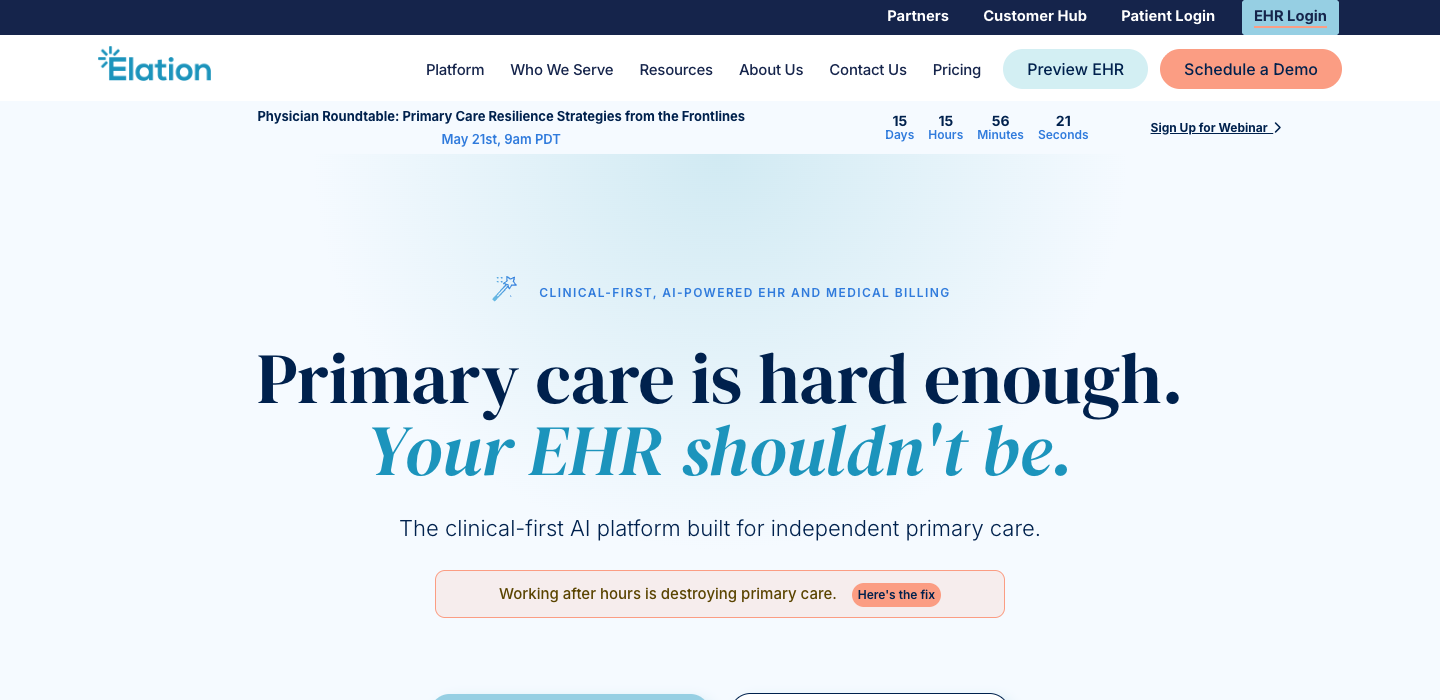
Healthtech · T2
Named villain: after-hours documentation
"Working after hours is DESTROYING primary care."
ONE OF ONLY TWO pages in 250 to name a concrete cost of inaction. The all-caps DESTROYING is not a typo... it’s the volume the founder talks at.
The pattern
Every villain above is something the buyer is currently experiencing, not something hypothetical. Contentful didn’t say "you might have content problems." They said "Sorry, content chaos... your time’s up." Guru didn’t say "AI could give wrong answers." They said "Stop running your business on confidently wrong AI." The mirror, not the threat. The diagnosis, not the warning.
08 - The Invisible Middle
The biggest cluster scores 12-18. Accurate. Forgettable.
78 of 220 pages... 38% of the entire dataset... sit in the 12-18 score band. They’ve avoided the worst sins. No AI-Parmesan, no FUD-led shouting, no obviously broken hero. They just don’t say anything memorable. Correct about themselves. Invisible to everyone else.
Pages stuck in the Invisible Middle
38%
78 of 250 companies. The single largest cluster on the 36-point scale. Avoided AI-Parmesan. Forgot to name a villain.
Six pages stuck in the middle
These aren’t bad pages. They’re not embarrassing. They’re just... there. Pull any of them up cold and you couldn’t describe what makes the company different from three competitors.

50%
INVISIBLE
B2B SaaS · T1
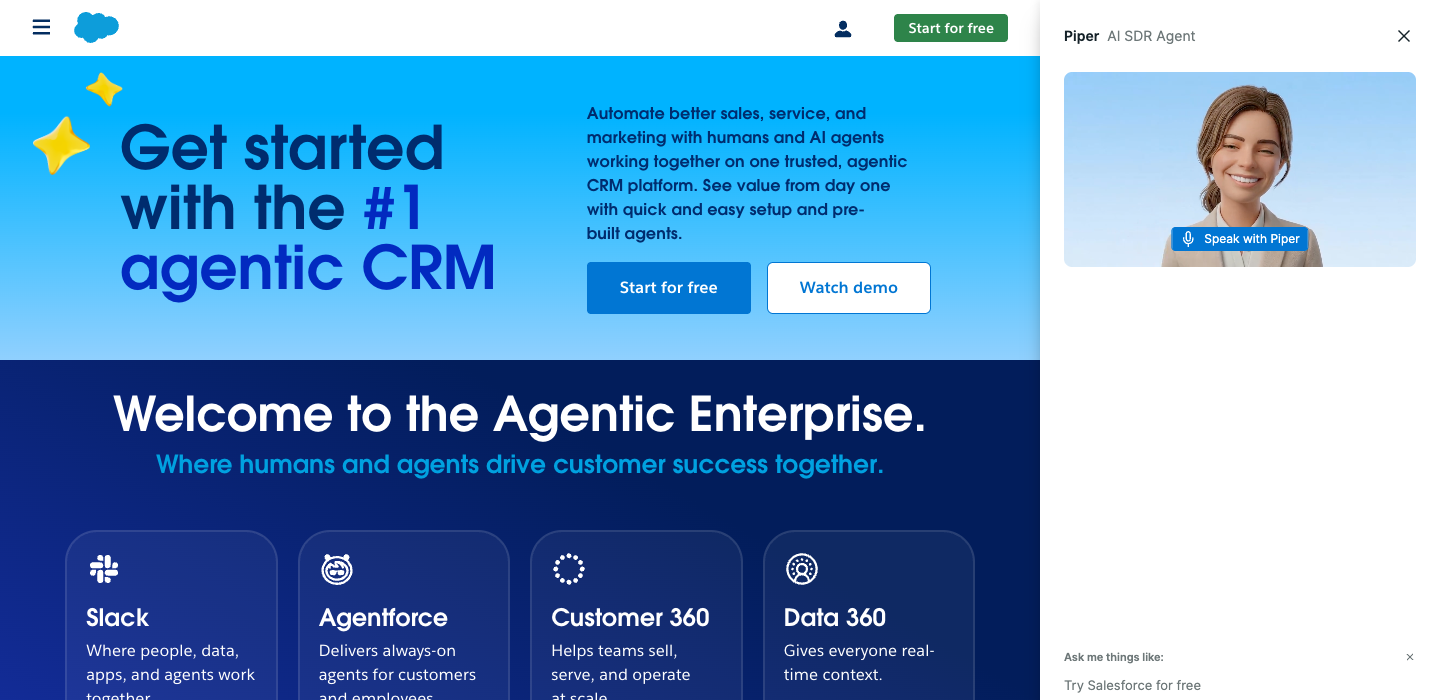
B2B SaaS · T1
"#1 Agentic CRM."
Names a category but rents it from analysts. No villain, no buyer in the hero.
How to escape the middle
Three moves. Name a specific villain the buyer is fighting right now. Name a concrete outcome the buyer can taste. Drop the AI sprinkle. Every page that scored 28+ did all three. Every page in the Invisible Middle missed at least two of them.
09 - The AI-Parmesan Effect
The more you brag about AI, the worse you score.
We coined the term ‘AI-Parmesan’ for the pattern... companies sprinkling ‘AI-powered’, ‘AI-native’, and ‘agentic’ on every line of the page like parmesan on weak pasta. The pattern was so consistent across 250 pages it made us re-check the data.
Zero AI mentions in hero
67%
APPROACHING
average sector score
3+ AI mentions in hero
33%
WEAK
average sector score
AI mention counts captured qualitatively from scoring notes, not as a formal column. Direction and magnitude consistent across the dataset.
The Anti-AI-Parmesan move
The highest-scoring AI companies in the dataset don’t lead with AI. They lead with the OUTCOME. The AI is invisible. The outcome is visible. That’s the difference between AI-Parmesan and AI that actually works.
94%
MAGNETIC
Cybersecurity · T3
Cybersecurity · T3
"Modern work broke IT security."
Co-leader. Sells AI-driven discovery. Zero AI in the hero.
83%
MAGNETIC
Wildcard · T3
Wildcard · T3
"The busywork runs itself."
‘HCP AI trained on 100M+ jobs’ is in the sub. Hero is about busywork, not AI.
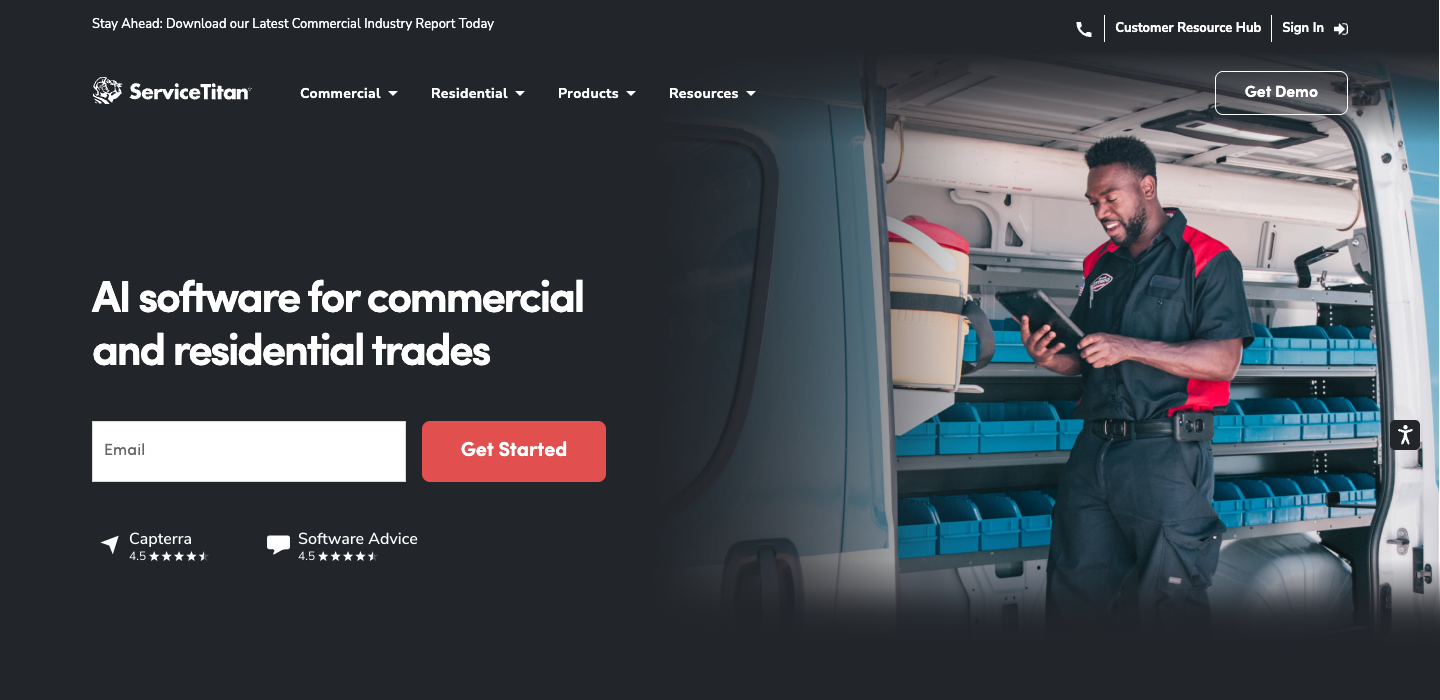
72%
APPROACHING
Wildcard · T2
Wildcard · T2
"#1 software for commercial and residential trades."
Zero AI mentions. 10+ customer metrics. All about outcomes.
What this means
Every "AI-powered" on your homepage is a vote against your buyer. The buyer doesn’t want AI... they want the outcome AI delivers. AI engines crawling your page can’t cite you for "AI-native, AI-driven, agentic, AI-first." They can cite you for "This CRM calls your leads for you." One line is a sentence. The other is parmesan.
10 - Five Unexpected Findings
Where the data surprised us.
Five cases that broke the pattern... or proved it harder than the headline does. Each one is grounded in a specific page, a specific score, and a specific reason.
01
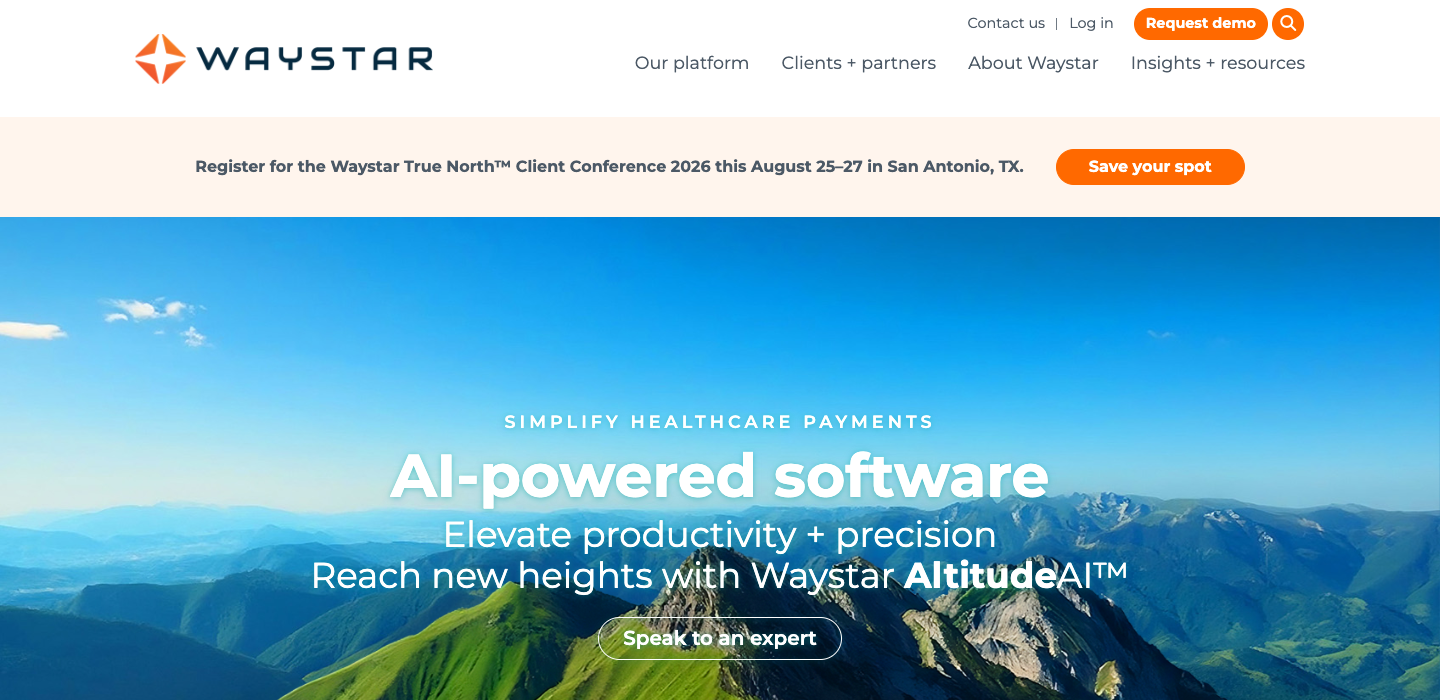
Waystar (T3) scored 14% ... CRITICAL.
"AI-powered software. Elevate productivity + precision. Reach new heights with Waystar AltitudeAI."
Branded AI product announcement over a stock mountain photo. Tells you nothing about who the buyer is, what problem they have, or why they should care. The T3 version of Palantir’s mistake... treating the homepage as a product launch poster instead of a buyer conversation. Proves size doesn’t protect you from bad messaging. Discipline does.
02
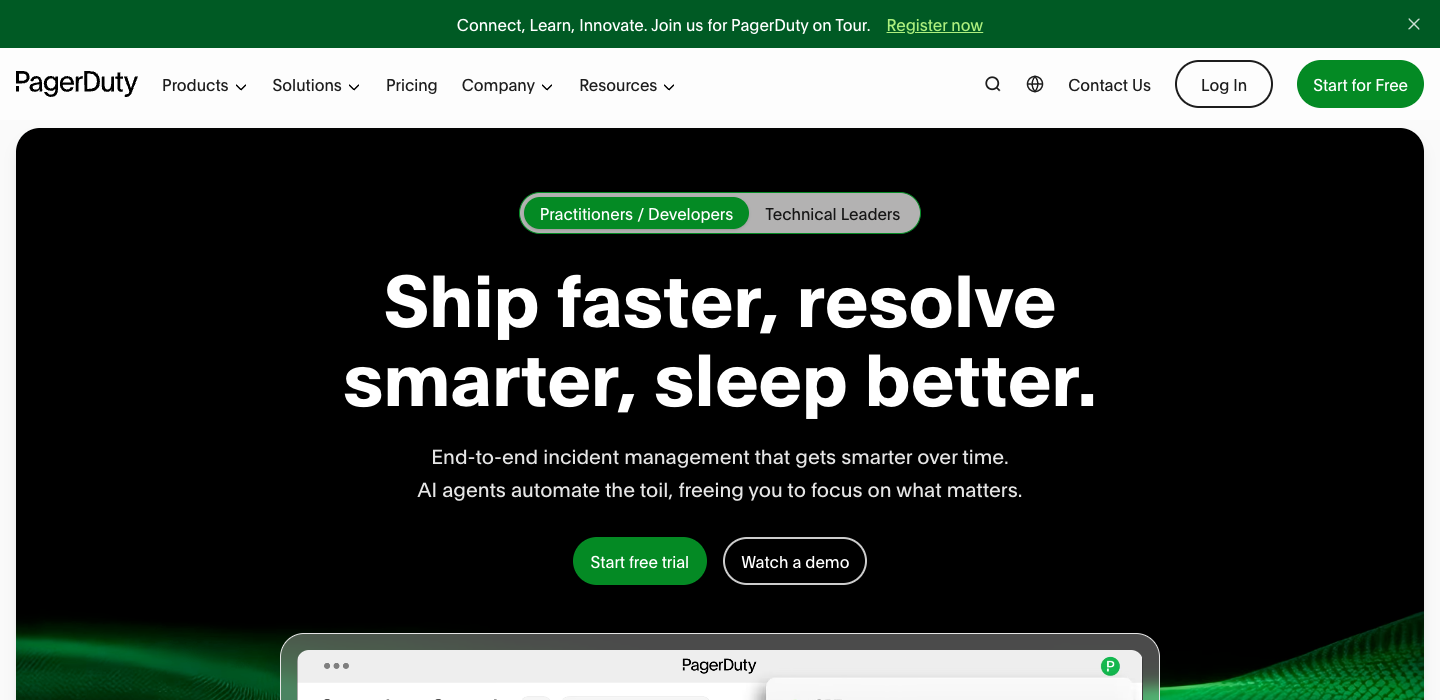
PagerDuty (T1) scored 72% ... APPROACHING with one word: sleep.
"Ship faster, resolve smarter, sleep better."
Every other T1 hero in the dataset speaks to business outcomes... revenue, efficiency, scale. PagerDuty is the only one that speaks to a PERSONAL outcome. On-call engineers don’t lie awake thinking about MTTR metrics. They lie awake because the pager might go off. ‘Sleep better’ meets them where they actually are. The difference between selling to the role and selling to the human.
03
Zapier (T1) hit 83% ... MAGNETIC. Same resources as Salesforce.
"Your tools. Your rules. Any AI."
Zapier has the same brand weight, same enterprise complexity, same budget as the Salesforces and Snowflakes of the world. They chose buyer-first, rebellion-forward, specific. Named the villain (waiting for permission). Spoke in the buyer’s voice. Brought proof (450K agents). The T1 average is low because most T1 companies CHOOSE vague messaging. Not because they have to.
04
Both #1 companies sell AI. Neither mentions it in the hero.
"Close CRM (34): ‘This CRM calls your leads for you.’ Nudge Security (34): ‘Modern work broke IT security.’"
Close CRM sells an AI agent (Chloe). The hero never says AI. Nudge Security sells AI-driven shadow IT discovery. The hero never says AI. The AI is invisible. The OUTCOME is visible. The best AI companies don’t lead with AI. They lead with the outcome AI delivers. That’s the difference between AI-Parmesan and AI that actually works.
05
‘Content chaos’ and ‘confidently wrong AI’ are the two best named villains in the entire dataset.
"Contentful (30): ‘Sorry, content chaos... your time’s up.’ Guru (33): ‘Stop running your business on confidently wrong AI.’"
Both name something the buyer is CURRENTLY experiencing. Not something hypothetical. Contentful doesn’t say ‘you might have content problems.’ They say ‘Sorry, content chaos... your time’s up.’ Guru doesn’t say ‘AI could give wrong answers.’ They say ‘Stop running your business on confidently wrong AI.’ The mirror, not the threat. The diagnosis, not the warning.
11 - The Leaderboard
All 216 homepages, scored high to low.
The full dataset, scored by Claude against the 18-criteria rubric. Tier badges show revenue band (T1 = $500M+, T2 = $50-500M, T3 = $5-50M). Score is out of 36. The notes column captures the hero copy or the standout messaging move.
216 unique companies, de-duplicated from a 225-row scoring sheet. Industries: Healthtech, B2B SaaS, Fintech, Cybersecurity, AI/Data, plus a Wildcard cross-sector bucket (HR Tech, Legal Tech, Construction Tech, Supply Chain, Sales Enablement). Score your own homepage with the Homepage Scorer.
12 - 26 Ways to Be Invisible
26 Ways to Be Invisible
Every one of these showed up in the data. Some showed up 200 times.
From the 18 Criteria
No 7-Second Clarity
If a stranger can't tell what you do in 7 seconds, they won't spend 8 figuring it out.
No Problem Leadership
If you lead with your product instead of your buyer's problem, you've already lost the conversation.
No Rebellion
If your buyer doesn't see you fighting against the status quo, neither will they.
No Transformation
If your buyer can't see the before and after, they have no reason to move.
No Named Villain
If you don't name the villain, your buyer doesn't recognize why they need you.
No Cost of Inaction
If your buyer doesn't feel the cost of doing nothing, doing nothing is exactly what they'll do.
No Buyer Language
If your homepage sounds like your internal brainstorm and not your buyer's Monday morning, you're talking to yourself.
Too Much "We"
If every sentence starts with your company name, your buyer sees a mirror pointed the wrong way.
No Answers
If your homepage can't answer what you do, for whom, and why anyone should care, you don't have a homepage. You have a placeholder.
No Differentiation
If you could swap your logo with a competitor's and nothing feels wrong, you don't have positioning. You have a template.
AI-Parmesan
If your homepage sprinkles "AI-powered" on everything without saying what the AI actually does, you sound like everyone else who's also sprinkling "AI-powered" on everything.
No Clear Next Step
If your buyer has to guess what to do next, they'll do the easiest thing. Which is leave.
No Real Proof
If your social proof is logos without context, your buyer sees a wall of names and feels nothing.
No Specificity
If your claims could apply to any company in your industry, they apply to none of them.
Not Quotable
If an AI agent can't summarize what you do in one sentence, you're invisible to the fastest-growing discovery channel in B2B.
No Feeling
If your homepage doesn't make your buyer feel something, it won't make them do anything.
No Authority
If you claim expertise without showing evidence, your buyer hears every other company that also claims expertise.
Nothing Below the Fold
If your homepage is a hero and a footer, you're asking your buyer to decide on a headline. They won't.
From the Cross-Pattern Findings
The Enterprise Trap
If your website looks and sounds like a Fortune 500 but you're not one, you have a messaging problem. The enterprises in our study scored 30% lower than growth companies. Don't copy the companies losing this race.
The Everyone Problem
If your solution is for everyone, it's for no one. Vertical SaaS companies in our data averaged 23/36. Horizontal "for all businesses" companies averaged 16/36.
The AI Substitution
If you replaced your product's name with "AI-powered platform" and the sentence still works, you haven't said anything. The more AI mentions on the homepage, the lower the score. Every time.
The Free Trial Effect
If you're hiding behind "Book a Demo," you might be hiding something else. Companies with "Start for free" averaged 22/36. Companies with only "Book a demo" averaged 15/36. Free trials force clarity.
The Developer Standard
If engineers use your product, your messaging better be precise. Developer-first companies averaged 24/36. Engineers punish vagueness. Everyone should write like they're writing for engineers.
The Invisible Middle
If your homepage accurately describes what you do but says nothing interesting about it, you're the conference booth people walk past. The most common score range was 12-18/36. Accurate but invisible.
The Cybersecurity Paradox
If you sell to the most informed buyers in B2B and your homepage says the least, something is deeply wrong. T1 cybersecurity averaged 13/36. The worst-scoring segment in the entire study.
The Anti-Parmesan Play
If you sell AI, the highest-scoring move is to tell the truth about what's broken with AI. Guru and Lavender named AI as the villain and scored in the top 10. The rebellion against AI-parmesan works best from inside the AI industry.
13 - Your Turn
What 250 homepages just proved
In the age of AI agents, the truth is the one asset that compounds. Build it once. Deploy it everywhere. The companies at the top of this leaderboard aren’t doing anything magical. They’re just telling the truth about what they do. And in 2026, that truth is now readable by both humans and machines.
This is what PitchKitchen’s Magnetic Messaging Framework builds: the documented truth of your perspective, your rebellion against the status quo, your case for why your solution is the only way forward. Designed to attract your ideal customer, repel everyone else, and train your AI Brand Twin to scale that truth across every piece of marketing and sales enablement you produce.
Every word of your thought leadership, every webinar, every email, every LinkedIn post... should be informed by this truth. The companies at the top of this leaderboard have it, whether they call it that or not. The companies at the bottom don’t. They’re using AI to scale generic.
How does your homepage score?
The 18-criteria rubric isn’t locked in our heads. Score your own homepage against the same rubric we ran on these 250 companies and get your results in 30 seconds. If the score isn’t what you wanted, the 90-Day Magnetic Messaging Sprint is how we fix it together.
Score your homepage (free)
Homepage Scorer
Enter your URL, get scored on the same 18 criteria we used on 250 B2B companies. Results in 30 seconds. The fastest way to know exactly where you stand.
Get your score →
Fix the score
90-Day Magnetic Messaging Sprint
A fixed-price rebuild with an AI Brand Twin. We rebuild the homepage, the story, and the messaging your AI copilots use, in 90 days. Designed for B2B founders at $5M-$75M.
See the 90-Day Sprint →
About the author
Greg Rosner
Founder of PitchKitchen. Creator of the Magnetic Messaging Framework. Author of StoryCraft for Disruptors. Greg has rebuilt the homepage, story, and AI Brand Twin for 100+ B2B companies of all sizes, from $5M scale-ups to enterprise rebellions.
Last updated: